The Semantic Layer
CORPUS is being built in the open. Some of what you read here is live, some is still design intent — expect it to evolve.
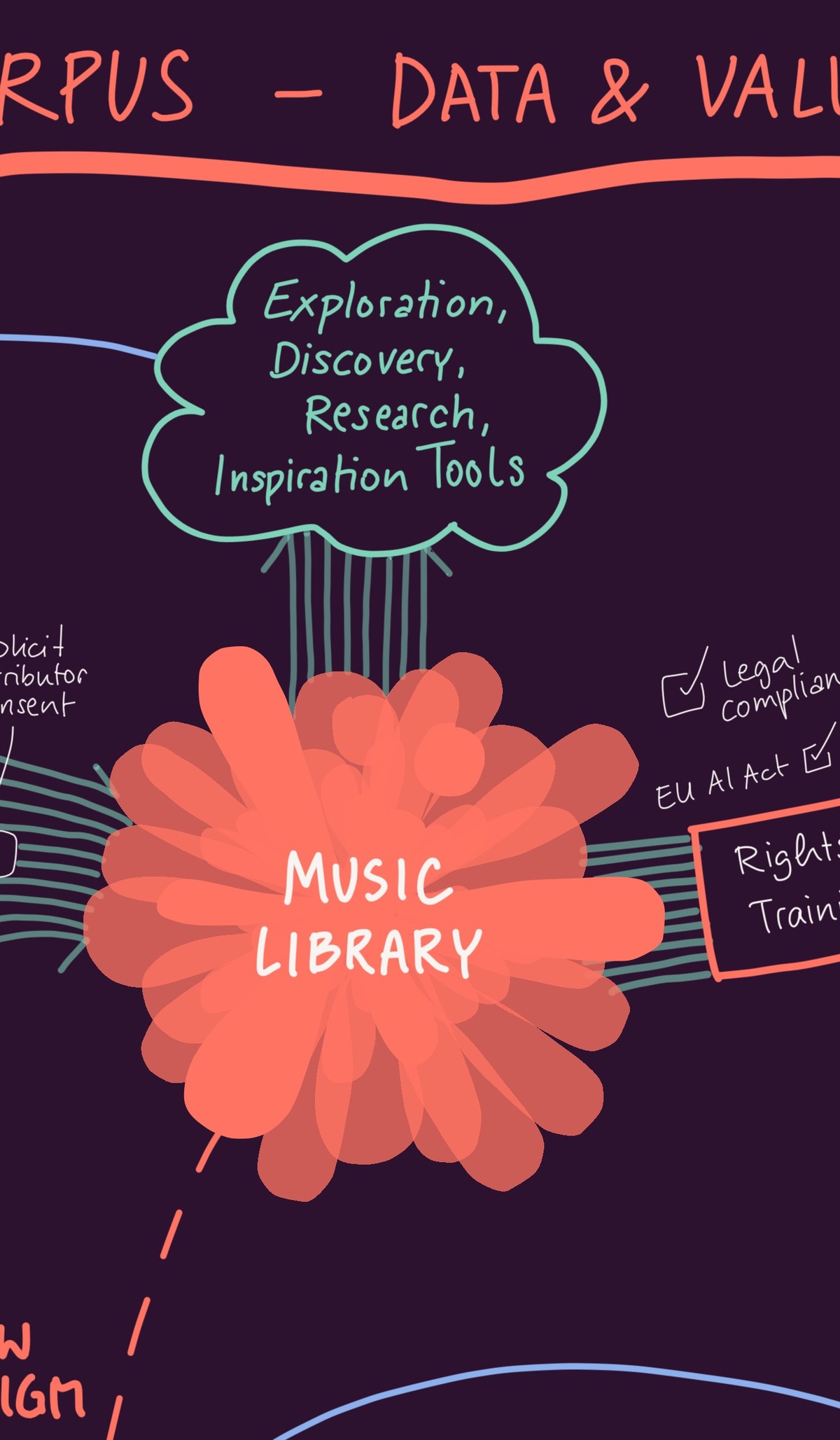
Raw audio is not a corpus you can build with. A million files on disk are a million files on disk. What makes the CORPUS library operational — for model training, for catalogue search, for narrative retrieval — is the annotation layer that sits on top of the audio: a structured, high-resolution description of what each track actually contains.
This layer is Layer 3 of the three-layer architecture: the proprietary semantic pipeline. It is also the primary source of CORPUS's competitive differentiation, and the foundation of every product the protocol ships.
Descriptions, not tags
Existing music-tagging systems work by reducing each track to a small set of categorical labels — Rock, 71 BPM, Male vocal, Piano. That works until the track is more than one thing. A multi-part rock ballad that opens with a soft melancholic piano around 71 BPM, builds into a layered rock anthem, accelerates into an operatic section at 151 BPM, then settles into a driving rock groove at 138 BPM cannot be honestly compressed into "Rock, 71 BPM". The tags are wrong for most of the song.
CORPUS writes 300- to 500-word descriptions per track instead, across four dimensions:
- What the music is — instrumentation, structure, key, tempo movements.
- What the music does — emotional arc, dramaturgical function, dynamic behaviour.
- Where the music belongs — genre, tradition, cultural context.
- How it would work as potential film music — scene fit, narrative function, dramatic role.
The framework was developed with musicologists and composers, then automated so the same rigour holds at catalogue scale. Semantic search runs against these descriptions, not against tags — which is why a search can resolve a brief the tag schema never anticipated. The longer-form argument for this approach is at An Objective Description of Music in the journal.
A concrete consequence: leading tag-based systems have labelled a Yoruba Afrobeat track as Latin, and a Portuguese fado as Klezmer. A description sets down what it hears even when a single label gets it wrong.
Two outputs from one pipeline
The same annotation layer produces two distinct things:
- Training-ready subsets. Models trained on CORPUS are not trained on the whole library — they are trained on slices selected for an application domain (mobility, healthcare, games, advertising). The annotation layer is what lets a subset be defined precisely: which tracks, by which criteria, with which characteristics.
- A search and retrieval interface. The same descriptions that let a training set be specified let a human ask the corpus for music. Three search modes — precision, audio similarity, narrative — sit directly on top of the annotation index. See Three Modes of Search.
What this enables
A few things that are not possible without it:
- Subset specification at the resolution applications actually need. "Lower-energy ambient music for a clinical setting" is a vague phrase that the annotation layer turns into a defensible, reproducible set of tracks.
- Provenance from query to result. Every track in a search result carries its full upload-time agreement, ownership splits, and consent record. The annotation layer does not replace that — it makes it queryable.
- Catalogue intelligence as a product. The same pipeline run against a partner's catalogue produces the same kind of operational index — see Catalog Intelligence.
Where this sits in the protocol
The annotation pipeline is proprietary. That is a deliberate part of the three-layer separation: the protocol is open because trust requires transparency, the data is controlled because protection requires enforcement, the pipeline is proprietary because the depth and quality of annotation are what makes the training data valuable beyond its raw audio content.
In benchmark comparisons against existing commercial music-tagging systems — Cyanite, Bridge.audio, AIMS — CORPUS's description quality leads on a track-by-track basis. That gap is the substance of the differentiation, not a marketing claim about it.
Next: Three Modes of Search.