How Contributions Are Evaluated
CORPUS is being built in the open. Some of what you read here is live, some is still design intent — expect it to evolve.
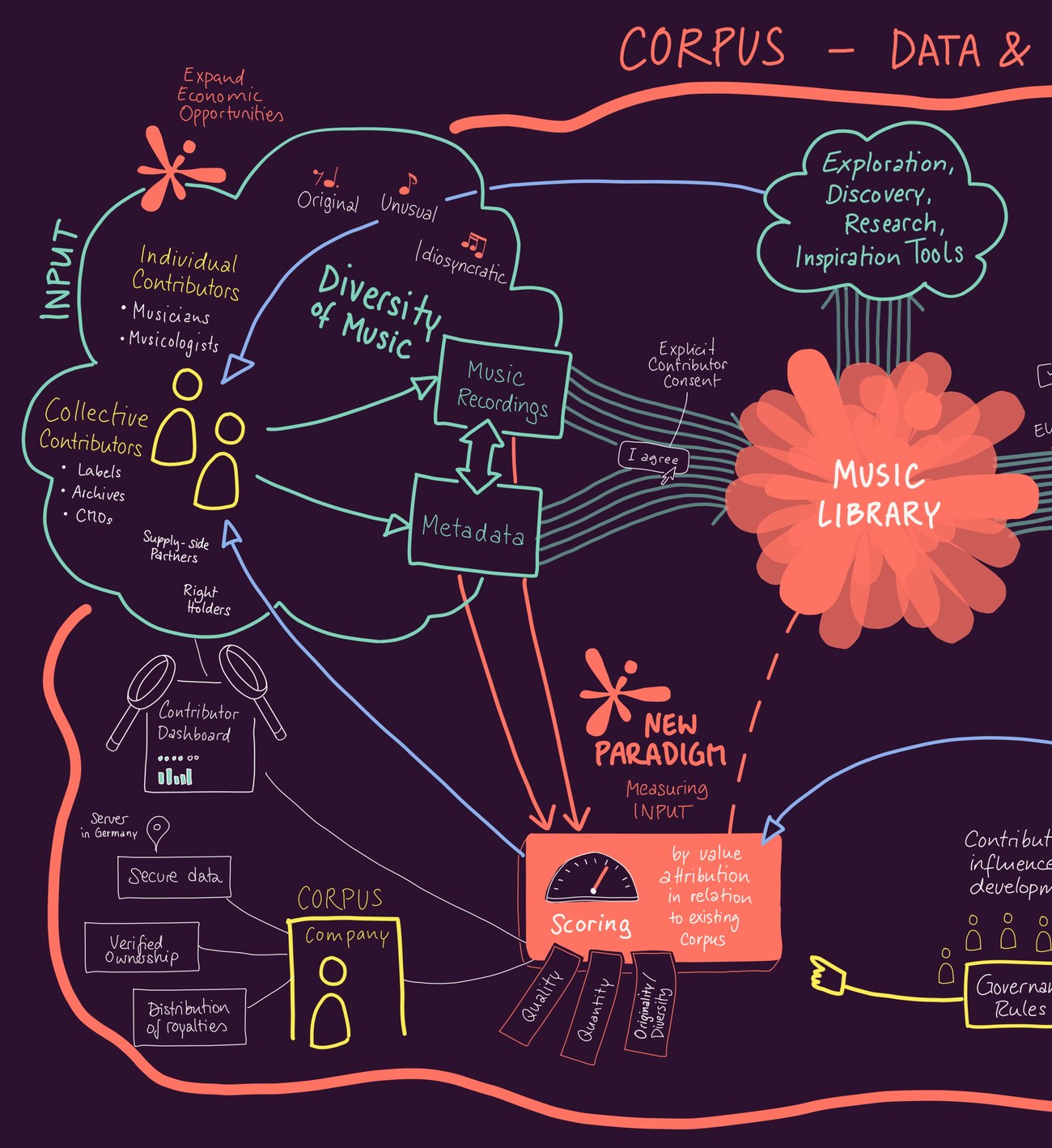
Unlike traditional licensing, where royalties follow the reproduction of finished works, CORPUS allocates value on the input side. Each contribution is assigned a weighting at the moment it enters the corpus, and that weighting determines its share of future revenue when models trained on the library are licensed.
Scoring happens once — at ingest — and stays fixed except for metadata improvements or fraud/error corrections. The deeper function of the scoring system is to encode a specific economic logic: the value of each contribution is defined by its relationship to the whole, not by its performance in a market of discrete products.
Three dimensions determine the weight.
Quantity
Every contribution expands the breadth of the corpus. A baseline score ensures participation itself is rewarded.
Quality
Works must meet technical and descriptive standards. Clean recordings, accurate metadata, and consistent annotation raise the weighting. Non-musical content, illegal samples, corrupted files, and AI-generated material are filtered before the score is set.
Diversity
Contributions that expand the corpus into underrepresented areas earn extra weight. Originality is measured through relational analysis, not surface-level tags: the system evaluates how a work positions itself relative to existing data points, capturing structural, stylistic, and cultural distinctiveness. This rewards genuine expansion rather than saturation, and counters historical biases such as the overrepresentation of Western commercial music in training datasets.
Why this inverts streaming logic
In the streaming economy, algorithms promote what resembles what has already succeeded; economic gravity pulls the entire catalogue toward a narrowing center. Difference is a disadvantage.
In CORPUS, difference is the engine. An Anatolian bağlama recording, a Tuvan throat-singing session, an experimental prepared-piano improvisation — these are not niche curiosities. They are high-value assets, because they expand the expressive range of every model trained on them. Originality becomes progressively harder to achieve as the dataset grows, which pushes contributors toward new territory rather than repetition.
The full mechanics — base points by format, integrity filters, production-quality assessment, relational originality scoring, and metadata contributions — are described in The Scoring System in Detail.
Next: The Scoring System in Detail.