Access Models
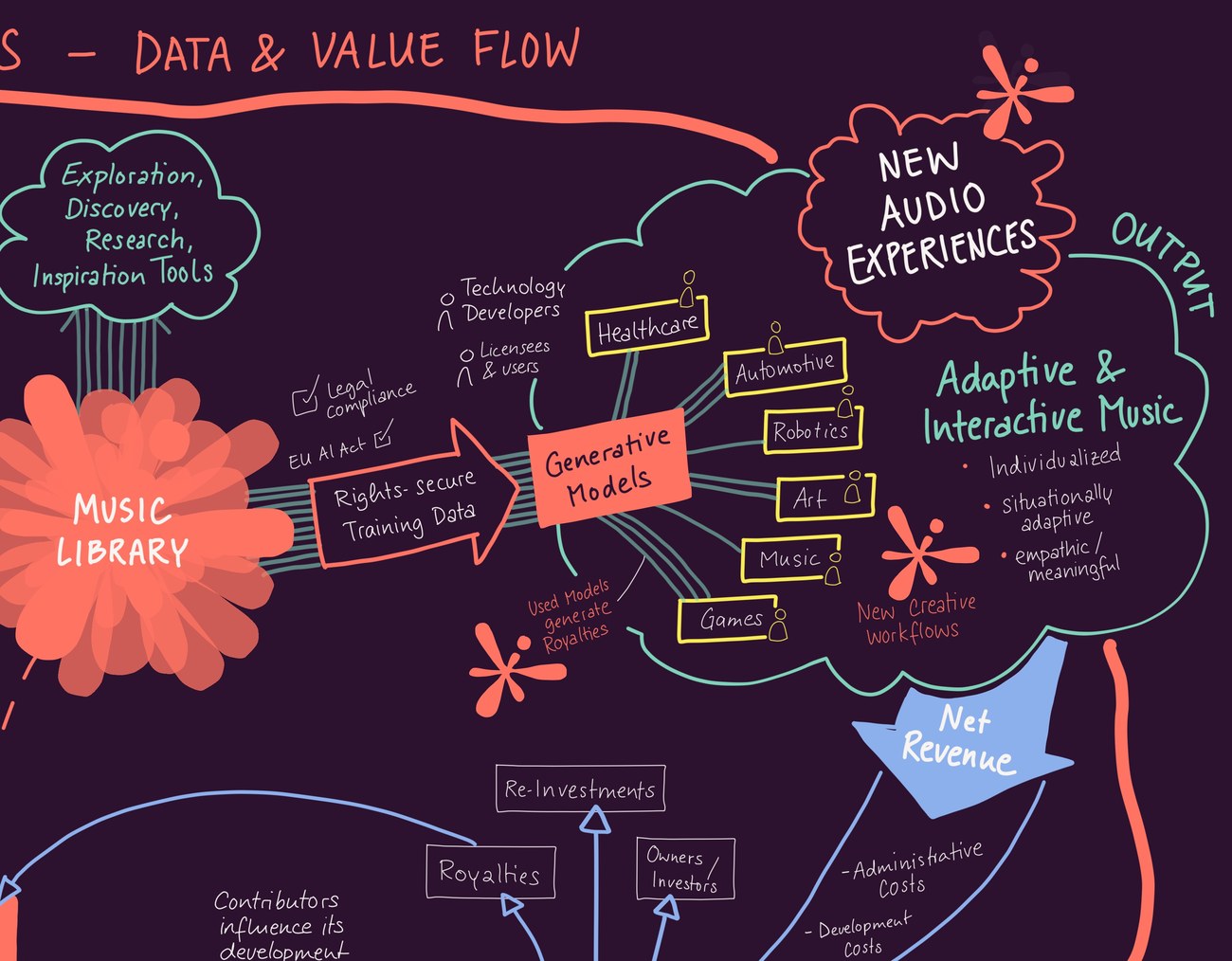
CORPUS is a model licensor, not a dataset licensor. We train models on the licensed corpus and license the resulting models to partners for deployment in their products. The training data itself does not leave our infrastructure. This page explains what that looks like in practice.
Every track that contributes to a CORPUS-trained model is licensed by explicit contributor opt-in, every training run is logged in an append-only provenance registry, and every deployed model feeds back into contributor royalties and CRPS. The integrity of that chain is what the architecture protects, and it is the reason the data stays on our side.
Licensing trained models
CORPUS trains models for specific application domains — adaptive sound for mobility, healthcare and therapeutic deployments, interactive media, advertising, cultural and educational tools — and licenses the trained models to partners building products in those domains.
What a licensee receives is a deployable model with the audit trail behind it: the model weights under a deployment license, the provenance record for the training run, and the documentation that downstream compliance and procurement teams need to defend the integration. The concrete shape of the license — how it scales with deployment volume, where it runs, what redistribution looks like — is worked out per engagement, because the right shape for an in-vehicle deployment is not the right shape for a clinical device or a game engine.
Models are trained on a defined slice of the corpus appropriate to the application. The annotation layer is what makes this operational: subsets can be specified precisely enough to be useful, the works that enter them are identified, and the royalty flow back to the contributors whose music shaped the model is traceable. See The Semantic Layer for the annotation stack itself, How Royalties Flow for the contributor side, and Applications for the domains where CORPUS-trained models are being developed.
For partners whose primary need is annotation and search over their own catalogue rather than a trained model, the same pipeline is available as a direct product. See Catalog Intelligence.
Federated training as an option
In principle, partners with their own model architectures can train inside CORPUS infrastructure rather than license a pre-trained model: the licensee submits architectures and training configurations, the run executes on our servers against the licensed corpus, and only the resulting model weights and audit logs leave. The data stays. This exists primarily to protect the terms under which contributors licensed their work — letting the dataset out, even to a trusted partner, would change a relationship the licensing terms do not cover.
In practice, the federated path is operationally involved and we have not validated it at scale. Treat it as a possibility to raise in conversation if a partner's roadmap genuinely requires custom training, not as a standard offering. The default route, and the one we recommend, is licensing a CORPUS-trained model.
The point of contact for working out which path fits is in Getting Started.